

球速体育网站:Qwen25登全球开源王座!72B击败LIama3405B轻松胜GPT-4o-mini
更新时间:2024-09-20
跟上一代相比,几乎实现了全面提升,尤其在一般任务、数学和编码方面的能力表现显著。
值得注意的是,此次Qwen可以说是史上最大规模开源,基础模型直接释放了7个参数型号,其中还有六七个数学、代码模型。

他们研究表明,用户对于生产用的10B-30B参数范围以及移动端应用的3B规模的模型有浓厚兴趣。
因此在原有开源同尺寸(0.5/1.5/7/72B)基础上,还新增了14B、32B以及3B的模型。
同时,通义还推出了Qwen-Plus与Qwen-Turbo版本,可以通过阿里云大模型服务平台的API服务进行体验。
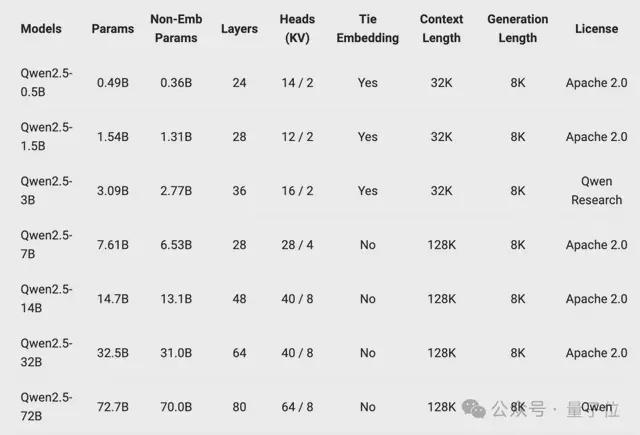
其次,预训练数据集更大更高质量,从原本7万亿个token扩展到最多18万亿个token。
然后就是多方面的能力增强,比如获得更多知识、数学编码能力以及更符合人类偏好。
此外,还有在指令跟踪、长文本生成(从1k增加到8K以上token)、结构化数据理解(如表格)和结构化输出生成(尤其是JSON)方面均有显著提升。
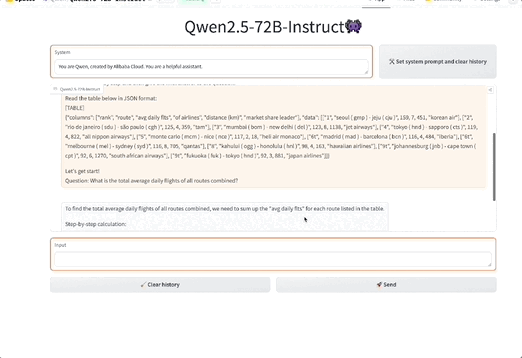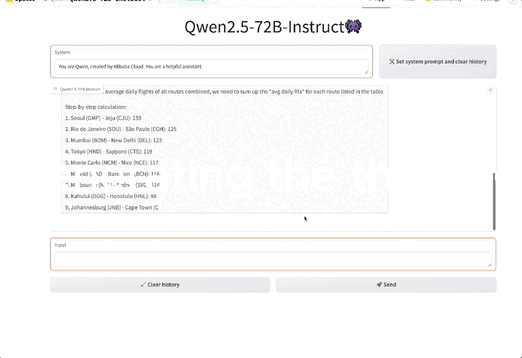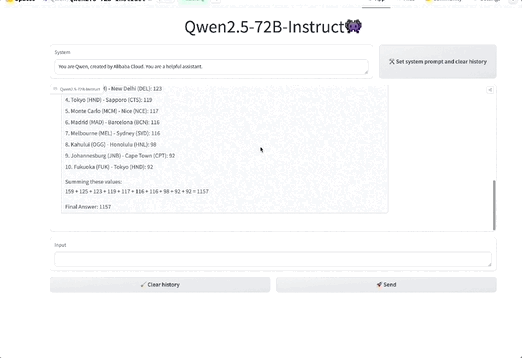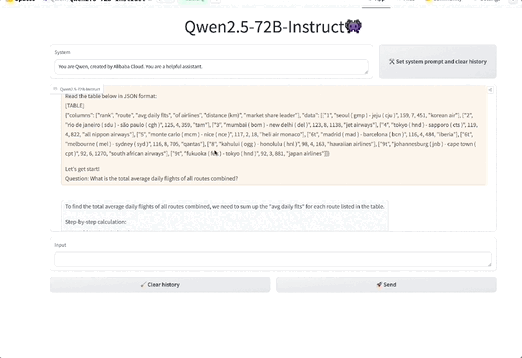
此外,Qwen2.5模型总体上对系统提示的多样性具有更强的适应能力,增强了聊天机器人的角色扮演实现和条件设定能力。
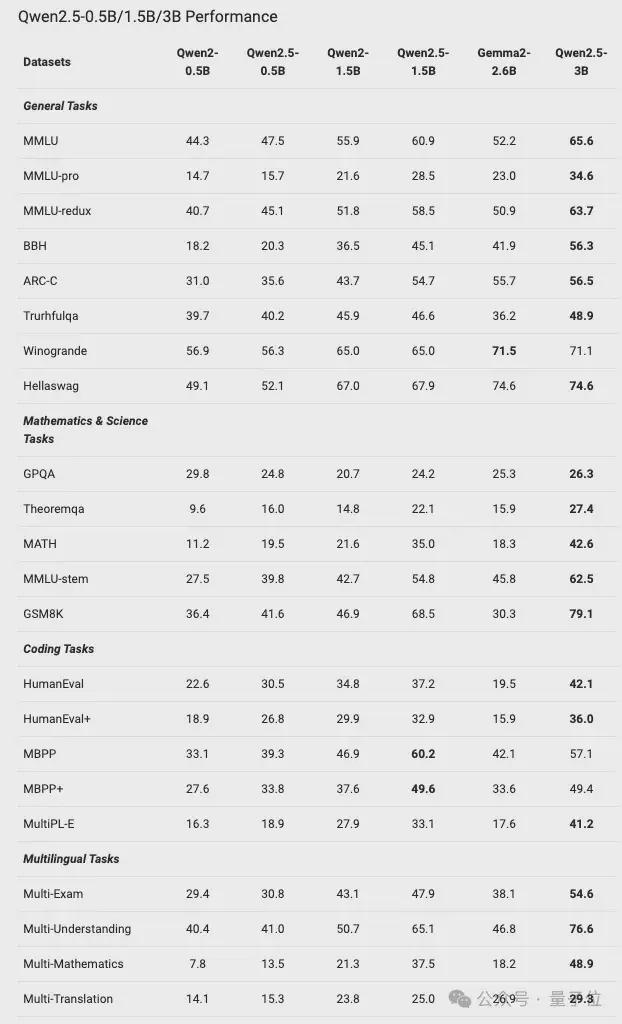
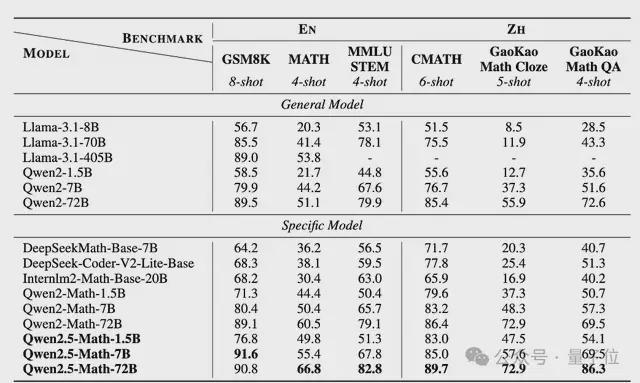
值得注意的是,Qwen2.5-0.5B型号在各种数学和编码任务上的表现优于Gemma2-2.6B。
Qwen2.5-Coder在更大规模的代码数据上进行训练,包括源代码、文本代码基础数据和合成数据,总计5.5万亿个token。
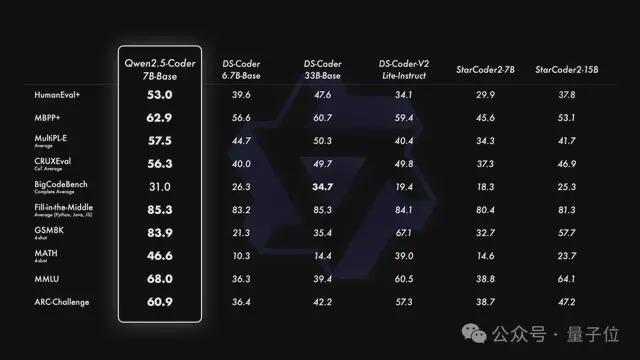
它支持128K上下文,覆盖92种编程语言。开源的7B版本甚至超越了DeepSeek-Coder-V2-Lite和Codestral等更大型的模型,成为目前最强大的基础代码模型之一。
而数学模型这边,Qwen2.5-Math主要支持通过CoT和TIR解决英文和中文数学问题。
 球速体育官方入口2147483647&quality=80&type=jpg />
球速体育官方入口2147483647&quality=80&type=jpg />
与Qwen2-Math系列仅支持使用思维链(CoT)解决英文数学问题不同,Qwen2.5-Math 系列扩展支持使用思维链和工具集成推理(TIR)解决中英文数学问题。
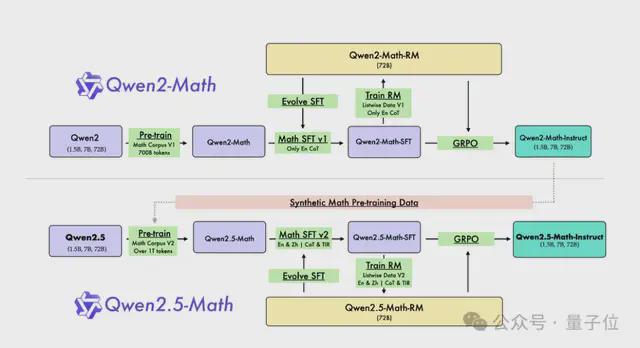
从网络资源、书籍和代码中收集更多高质量的数学数据,尤其是中文数据,跨越多个时间周期。
利用Qwen2.5系列基础模型进行参数初始化,展现出更强大的语言理解、代码生成和文本推理能力。
最终实现了能力的提升,比如1.5B/7B/72B在高考数学问答中分别提升了 3.4、12.2、19.8 分。
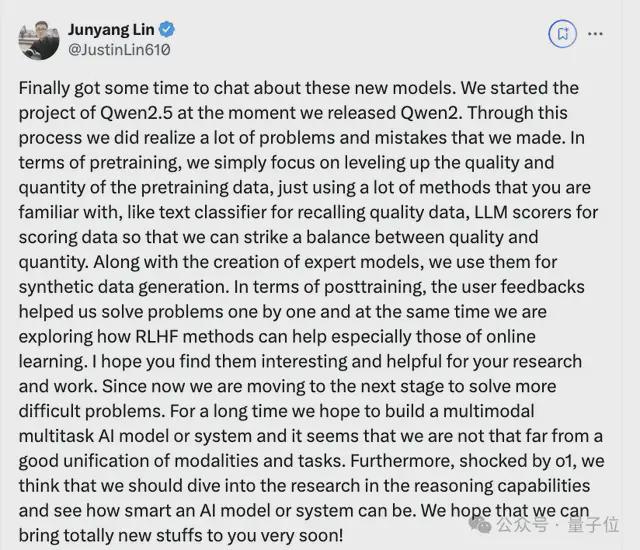
比如在预训练方面,他们们只是专注于提高预训练数据的质量和数量,使用了很多大家熟悉的方法。
比如文本分类器用于召回高质量数据,LLM 评分器用于对数据进行评分,这样就能在质量和数量之间取得平衡。
在后期训练时候,用户的反馈来帮助他们逐一解决问题,同时他们也在探索RLHF 方法,尤其是在线学习方法。
值得一提的是,在Qwen2.5预热之时,他们球速体育官方入口团队就透露不叫草莓,叫猕猴桃。

